
.svg)






It seems like everywhere you look, someone is either panicking about or celebrating Mythos, the superhuman AI that will break everything. Attackers will exploit systems at light speed! Defenders will be overwhelmed with vulnerabilities! The sky will fall! (And of course, AI stock prices will rise).
Some of these fears are certainly justified, and while initial reports do seem to show improvements in the latest crop of models, we have also been researching where AI can best improve our scanning and vulnerability research today. It turns out, current models are surprisingly capable already…
This post details how we are using LLMs to find novel vulnerabilities using code scanning frameworks alongside pre-Mythos models. And to evidence this claim, we’ll detail a remote, multi-stage SQL Injection 0-day we discovered in a 300k+ user WordPress plugin - fully automated from discovery through to exploitation, with no human in the loop.
Divide and conquer
The big issue when integrating AI with a code scanner is focus. LLMs are fantastic at taking small segments of code, or a description of a specific problem, and finding an interesting solution. But, point one at a large codebase and ask it to find security problems, and it will happily ingest every file in the repo trying to find everything. That's bad for your token budget, and worse for the model, by the time it's halfway through the codebase, its context window is full of code it doesn't need, and the bug you're looking for is sharing space with thousands of lines of unrelated noise.
For more complex bugs that require chaining multiple steps, you are then relying on your chosen framework’s ability to keep the right parts of the code in its memory at the right time or intelligently retrieve it when needed. In our experience, this leads to poor output rather than real and interesting bugs.
However, traditional code scanning frameworks already have tools for finding related code, and we don’t need to waste tokens doing that. This related code (which we are calling a program slice) is similar to when your IDE or LSP tool uses features like ‘find implementation’ or uses a call graph to find all of the functions called by the current function. These mature, well-tested tools can neatly solve the diluted context issue when dealing with large codebases.
Tokens in, 0-days out
To test it out, we built a pipeline which takes a codebase, runs it through a traditional code scanning engine (we use Joern), generates slices of code relevant to each finding, and uses the LLM to triage and exploit the issue. This design was inspired by nooperator’s work on Slice, although we use Joern rather than CodeQL, and designed the slicing algorithm quite differently to handle the specific vulnerability classes we are looking for.
We then fired it at the top 200 WordPress plugins, knowing that these are heavily picked over by bug bounty professionals, so finding an impactful bug would mean we have a process that can compete with human efforts.
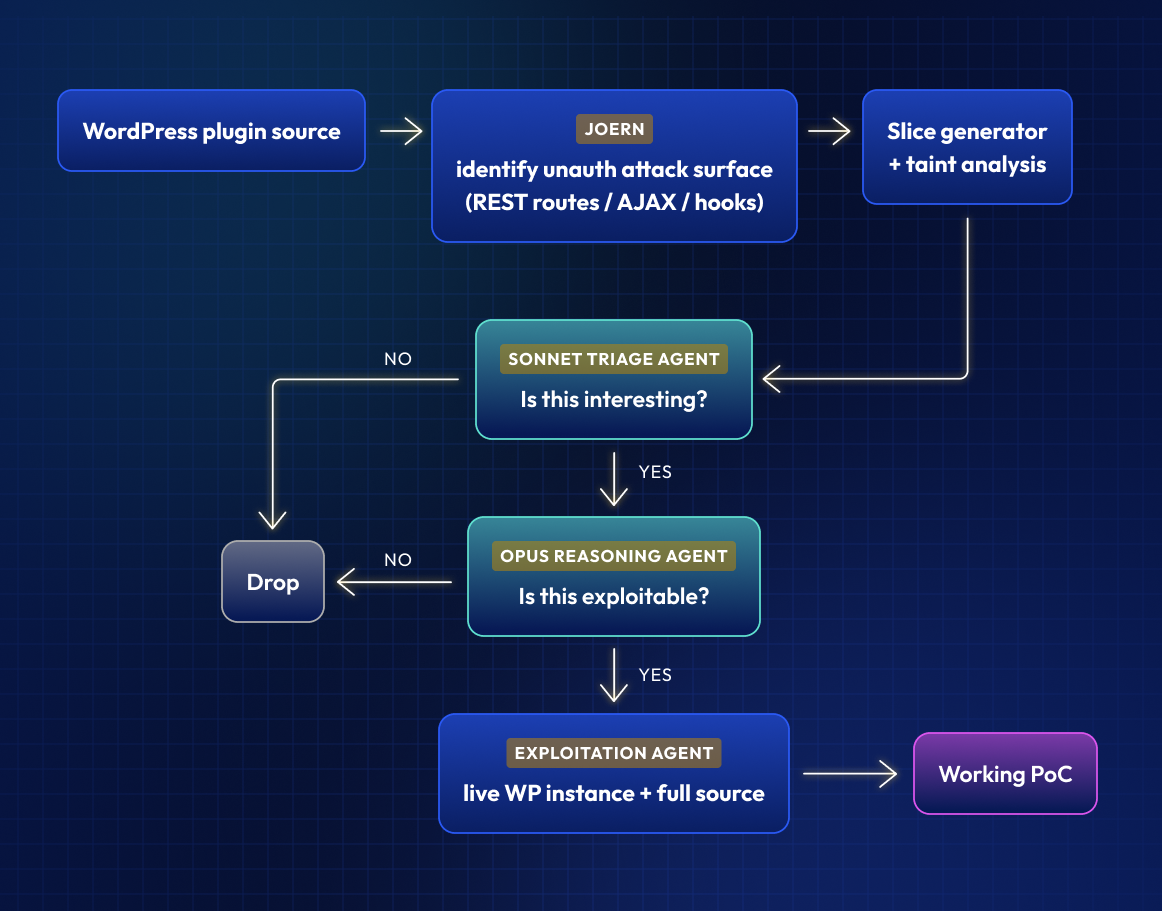
First, the codebase is run through Joern with a set of rules that are designed to look for interesting things. “Interesting things” is intentionally kept quite broadly scoped, to avoid creating rules that are too specific and might miss bugs. Since we have the triage agent filtering later anyway, we can err on the side of false positives.
For this experiment, we were looking for unauthenticated WordPress plugin attack surface, so we had the Joern script identify the different places in a WordPress script that can be affected by user input – REST routes, template hooks, nopriv AJAX calls, and so on.
Then, we had Joern generate a relevant slice of code for each WordPress hook – that means the function that is called when the hook is triggered, as well as every method that function calls, and the methods called by those functions, etc. At this stage we also apply some basic taint tracking techniques to rule out obviously safe functions – for instance, SQL or XSS inputs that go through a known safe sanitizer. Where we can verify statically that the code is safe to run, we drop those passing onto an LLM.
We pass each slice to a triage agent – a simple model (Sonnet in our test) whose job is to determine whether this is even interesting. Some hooks are quite obviously meant to be public and have no side effects, for instance, and can be ignored.
Finally, we pass the remaining slices that appear to be exploitable to a heavyweight agent (Opus in this case) to determine whether the case is exploitable. Because the entire call context fits into memory, the agent can focus on the case we want without getting lost in the source.
If the vulnerability is determined exploitable, we pass it to an exploitation agent to try and write an exploit. This agent has access to full source again (if needed) since it can now use targeted searches to find relevant code, and it will also spin up a Docker container running the software to test while developing – my colleague will be writing another post soon on how we’re integrating AI with VM to accelerate coverage of n-days for our customers.
The first vulnerability
The first interesting finding to be vended was CVE-2026-3985, a SQL injection vulnerability in the Creative Mail plugin. This one stood out to us for a few reasons:
- It’s high impact – an attacker gets read access to the database (admin hashes/secret tokens!)
- It requires multiple steps/requests to exploit, making it less likely to be detected by classic tooling
- The root cause of the vulnerability was hidden from the developer’s own static analysis tooling due to a mistake.
Successful exploitation does require that a second plugin, WooCommerce, is installed, as the vulnerability is in their WooCommerce integration. However, since using WooCommerce is a popular reason to use WordPress in the first place (with 7 million+ active installs), the combination is common.
The root cause of the issue can be found in has_checkout_consent() in DatabaseManager.php:
// phpcs:disable WordPress.DB.PreparedSQL -- Okay use of unprepared variable for table name in SQL.
$wpdb->prepare("SELECT checkout_consent FROM {$table_name} WHERE checkout_uuid = '{$checkout_uuid}'") Here, the $checkout_uuid variable is inserted into a raw SQL query rather than a variable in the prepared statement. The comment here starting // phpcs:disable prevents the developer’s code analysis tool from finding this mistake – they intended to silence the warning about the $table_name variable, which is safe, but it turns it off for the whole line.
The more interesting part is how an attacker can control $checkout_uuid, which happens in CheckoutManager.php. First, if the request has the parameter ce4wp-recover, this is read and stored into the session:
// Sanitize checkout UUID.
$this->checkout_uuid = filter_input(INPUT_GET, 'ce4wp-recover', FILTER_SANITIZE_STRING, FILTER_FLAG_NO_ENCODE_QUOTES);public function recover_checkout(): void {
// Set checkout session UUID.
WC()->session->set( self::CHECKOUT_UUID, $this->checkout_uuid );filter_input() is used, but with the option FILTER_FLAG_NO_ENCODE_QUOTES, which isn’t sufficient for preventing SQL injection.
On a subsequent request, the value is read back from the session, and the vulnerable function is used to make sure the visitor has permission:
$uuid = WC()->session->get( self::CHECKOUT_UUID ); $consent = CreativeMail::get_instance()->get_database_manager()->has_checkout_consent( $uuid );
if ( $consent ) {
$this->ce4wp_remote_post($requestItem, $endpoint);
} This means that a valid exploit requires two requests – one to store the malicious payload, and one to execute it. And since it’s a blind injection, that’s two requests per query, and then an SQLMap-style binary search to get useful information from it. We were surprised to find that, given access to an instance of the app to test against, the exploitation agent was able to one-shot this:
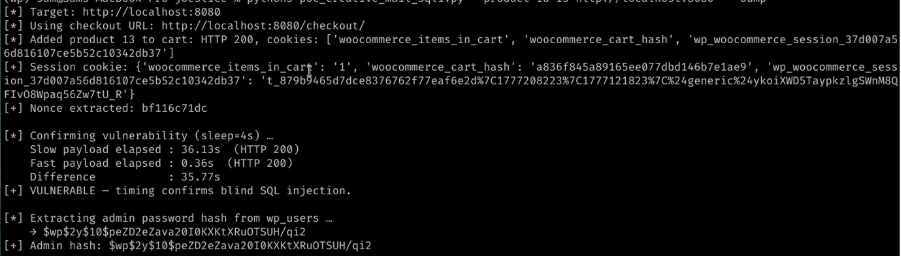
The proof-of-concept script can be found here, straight out of the exploitation agent, no edits. Note that it included both a check for the issue using a delay of 4 seconds (as the query is executed multiple times, the real delay is around 35 seconds), as well as a time-based search method which can extract password hashes to demonstrate impact.
This vulnerability was discovered independently by both Intruder and Dmitrii Ignatyev of CleanTalk Inc, who reported it to Wordfence first. As the information is now public, we are publishing our writeup, despite a patch not being available from the vendor yet.
The plugin has been disabled in the WordPress store pending a review, so can’t be installed currently – existing users should disable the plugin if they also use WooCommerce alongside it.
Why stop there?
The vulnerability detailed above is just the first of many! The vending machine doesn’t just have one vulnerability in it – indeed, we’re already finding more and reporting them to affected vendors. The rest are still under disclosure so we can’t mention them here, but we’ll be presenting the vending machine at some upcoming conferences, where and when we’ll be able to say more.
What this means for AI VR
It’s clear that AI has a big part to play in speeding up and streamlining vulnerability research. The current challenge is building the frameworks and surrounding infrastructure to get the best out of them.
Attackers are already using existing tools to feed AI focused, targeted input, dramatically increasing the signal to noise ratio and their chances of finding vulnerabilities fast.
For defenders, attack surface management remains vital, and automating discovery and patching of vulnerabilities is going to be increasingly important, too. You cannot wait a week to patch exposed services anymore.
Every novel bug we surface this way is one your next Intruder scan will find and report to you. Get set up in minutes to get covered.
Disclosure timeline
- 27/04/2026 – Vulnerability disclosed via the Wordfence Disclosure Program
- 18/05/2026 – Wordfence informed us that the report was a duplicate
- 19/05/2026 – Bug disclosed publicly by Wordfence and given CVE-2026-3985
- 11/06/2026 – Intruder writeup and POC released
Other research articles



